概述
AQS是J.U.C中的一个非常重要的类。
J.U.C是java.util.concurrent的首字母简称。而AQS是J.U.C下locks包的一个抽象类。
废话不多说,看一下类顶注释:(其中只截取了概述部分,并直接翻译一下,纯手翻,有些机械翻译,但能看懂)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/ **
*提供实现阻塞锁和相关的框架
*依赖的同步器(信号量,事件等)
*先进先出(FIFO)等待队列。该类旨在为
*大多数依赖于单独具有原子性值去展现状态的
*同步器提供有用基础内容。子类
*必须定义更改此状态的受保护方法,以及哪些方法
*根据被获取的对象定义该状态的含义
*或发布。鉴于这些,该类中的其他方法都会
*执行所有排队和阻塞方法。子类可以维护
*其他声明字段,但只有原子性的更新{@code int}值
*被操纵使用方法{@link #getState},{@ link
* #setState}和{@link #compareAndSetState}因为同步机制而被跟踪。
*
*
* <p>子类应被定义为非公共内部帮助类
*以用于实现他们封闭类的同步属性。
* 类{@code AbstractQueuedSynchronizer}没有实现任何
*同步接口。相反,它定义了许多方法,例如
* {@link #acquireInterruptibly}它可以被相关锁或同步器适当地调用
*去实现他们的public方法。
*
* <p>此类支持其中之一或同时两者模式,包括默认的独占模式和一个共享模式。
*当在独占模式中被获取时,
*通过其他线程的尝试获取是不会成功的。在共享模式中
*多线程获取可能(但不一定)成功。这个类
*不会“理解”这些差异,除非在
*方法层面,即当共享模式请求成功时,下一个
*等待线程(如果存在)也必须确定它是否可以
*请求获取。在不同模式下等待的线程共享
*相同的FIFO队列。通常,实现子类仅支持
*这些模式中的一种,但两者都可以在例如{@link ReadWriteLock}中发挥作用。
* 仅被独占模式或分享模式支持的子类
*不需要定义支持未使用模式中的方法。
*/
看一下它都有哪些方法:(大多数见名知意)

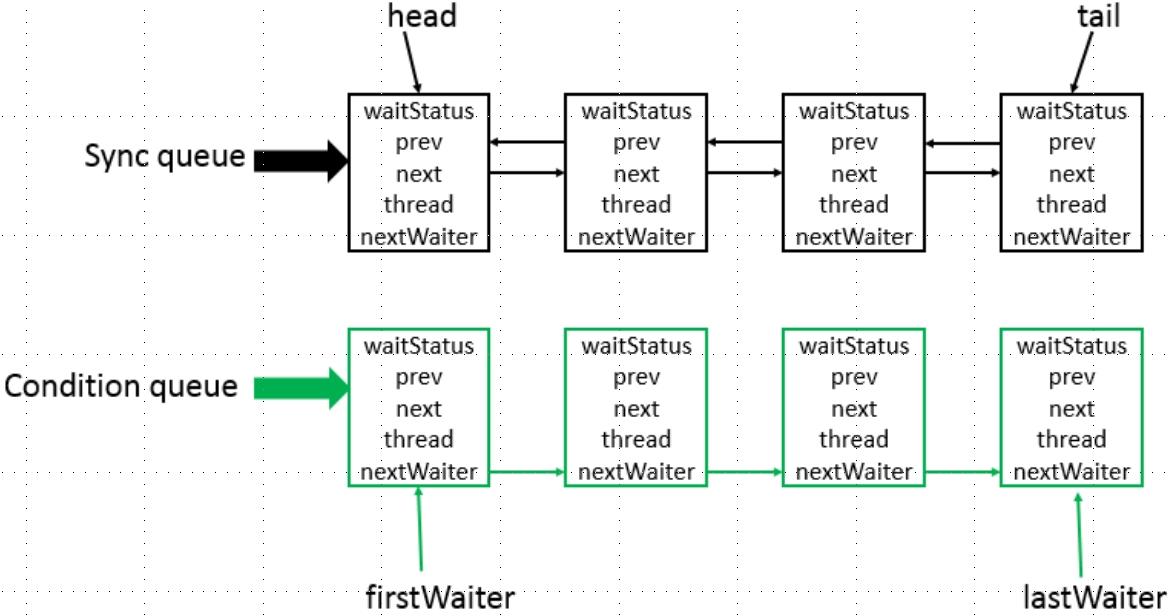
再看一下它的底层实现:
分析:
- 显然是使用双向列表,也是队列的一种。
- 上面的Sync queue是同步队列,实际是双向列表,其中的head节点主要用于后续的调度;
- 下面的Condition queue不是必须的,是一个单项列表;当使用到condition时才会用到此队列(可能会有多个)。
AQS的设计(注释中已提及,此处做总结。)
- 使用Node实现FIFO队列,可以用于构建锁或其他同步装置的基础框架。
- 使用int基础数据类型表示状态(state),在AQS的reentrant锁中state表示获取锁的线程数量。
- 通过继承并根据需要复写其中方法来使用该提供的框架。
- 子类通过继承并通过实现它的acquire和release等方法管理其状态。
- 可以同时实现独占锁和共享锁模式。它的子类不会同时使用两套API。即使是ReentrantReadWriteLock也是通过两个内部类读锁、写锁分别实现两套API来实现。
关键内容
AQS内部有一个等待队列,它是”CLH”锁队列的一个变种实现;CLH指的是Craig, Landin, and Hagersten这三个人的名字首字母拼装。(我猜是他们三个共同研究出的一种队列实现方式。)好吧真是个磨人的小妖精~再看一下源码中的说明。(只翻译了一部分,剩下的大家可以选择性地看看。)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72 /**CLH锁通常用于
*自旋锁。 我们现不将它们用作阻塞同步器,而是
*使用该相同的策略:通过持有一些它上个线程中的结点的控制信息。
*每个节点中的“status”字段跟踪是否有线程
*应该阻塞。 结点在其上个线程释放时会发出信号
*否则队列的每个节点通过持有一个等待的线程,成为一个
*特定通知式监视器。
*status字段虽然不控制线程是否被
*授予锁等。 一个线程可能会尝试去获取锁,如果他是在队列中的第一个时。
*但当是第一个时,并不能保证成功;
*它只给予线程去争取锁的权利。 所以现在被释放了锁的线程
*可能需要重新等待。
*
* <p>要排队进入CLH锁,您需要原子性地将其拼接为一个新的tail。
* 要出队列,您只需设置head(头部)字段即可。
* +------+ prev +-----+ +-----+
* head | | <---- | | <---- | | tail
* +------+ +-----+ +-----+
*
* <p>Insertion into a CLH queue requires only a single atomic
* operation on "tail", so there is a simple atomic point of
* demarcation from unqueued to queued. Similarly, dequeuing
* involves only updating the "head". However, it takes a bit
* more work for nodes to determine who their successors are,
* in part to deal with possible cancellation due to timeouts
* and interrupts.
*
* <p>The "prev" links (not used in original CLH locks), are mainly
* needed to handle cancellation. If a node is cancelled, its
* successor is (normally) relinked to a non-cancelled
* predecessor. For explanation of similar mechanics in the case
* of spin locks, see the papers by Scott and Scherer at
* http://www.cs.rochester.edu/u/scott/synchronization/
*
* <p>We also use "next" links to implement blocking mechanics.
* The thread id for each node is kept in its own node, so a
* predecessor signals the next node to wake up by traversing
* next link to determine which thread it is. Determination of
* successor must avoid races with newly queued nodes to set
* the "next" fields of their predecessors. This is solved
* when necessary by checking backwards from the atomically
* updated "tail" when a node's successor appears to be null.
* (Or, said differently, the next-links are an optimization
* so that we don't usually need a backward scan.)
*
* <p>Cancellation introduces some conservatism to the basic
* algorithms. Since we must poll for cancellation of other
* nodes, we can miss noticing whether a cancelled node is
* ahead or behind us. This is dealt with by always unparking
* successors upon cancellation, allowing them to stabilize on
* a new predecessor, unless we can identify an uncancelled
* predecessor who will carry this responsibility.
*
* <p>CLH queues need a dummy header node to get started. But
* we don't create them on construction, because it would be wasted
* effort if there is never contention. Instead, the node
* is constructed and head and tail pointers are set upon first
* contention.
*
* <p>Threads waiting on Conditions use the same nodes, but
* use an additional link. Conditions only need to link nodes
* in simple (non-concurrent) linked queues because they are
* only accessed when exclusively held. Upon await, a node is
* inserted into a condition queue. Upon signal, the node is
* transferred to the main queue. A special value of status
* field is used to mark which queue a node is on.
*
* <p>Thanks go to Dave Dice, Mark Moir, Victor Luchangco, Bill
* Scherer and Michael Scott, along with members of JSR-166
* expert group, for helpful ideas, discussions, and critiques
* on the design of this class.
*/
小结: AQS内部维护一个CLH队列来管理锁,线程会首先尝试获取锁,如果获取失败,则将就将当前线程以及等待状态等信息包成一个Node结点,加入到同步队列SyncQueue中,当当前结点为head的直接后继时才会不断尝试继续获取锁。如果失败则会阻塞自己直至自己被唤醒。当持有锁的线程释放时,队列中的后继线程才会被唤醒。
AQS的同步组件简介
此处仅做组件的简单的提出,后续会有详细的手记说明。
CountDownLatch
是闭锁,通过计数来保证线程间是否需要阻塞。
Semphore
控制同一时刻并发的线程数量。
CyclicBarrier
同CountDownLatch相似,均可以阻塞线程。
ReentrantLock
重入锁。后续手记中会详述。
Condition
使用时需结合ReentrantLock。
FutureTask
后续会有FutureTask的详细介绍……