为什么学习编译器编写技术?
我们都想当然的认为对编译器和解释器学习了个大概,因为你在开发中需要聚焦在编写和调试程序上,你甚至不需要思考编译器的工作机制。
你或许仅仅在搞错语法编译器抛出错误信息后才留意到编译器的存在。如果没有语法错误,那么编译将会生成正确的代码无疑。如果你的程序运行失常,你有可能怪罪编译器,但大多时候,你会发现错误在你的程序中。
以上情形通常会出现在你在使用某个流行编程语言(比如Java或C++)它的编译器、解释器和IDE都给你准备好了的时候。这先聊到这。
不过最近我们看到很多新编程语言在被开发。驱动力包括www(比如HTML5)和与基于web的应用相适应的新语言(典型比如PHP,纯web)。对程序员生产力的更高要求催生与具体应用领域紧密结合的新语言(这个可以举很多例子,比如为系统管理员的各种Shell语言,为数据库开发的各种SQL/NO SQL语言,为电路板/DSP开发的类VHDL语言等,为工作流开发的各种BPM语言等)。你可能非常期待自己有天能发明个新脚本语言表达算法或控制与你领域相关的流程。如果你要发明新语言,对应的编译器和解释器必不可少。
编译器和解释器本身很好玩,但你前面注意到了,任何一个都不是个小程序,要开发成功相关的技能,现代软件工程法则和良好的OO设计思想必不可少。除了学习编译器解释器工作机制带来的满足感外,你也要笑着面对编写它们带来的挑战。
概念设计
为接下几章做准备,让我们重温编译器和解释器的概念设计
设计笔记:程序的概念设计是它的软件架构的一个高级视图。概念设计包含程序的主要组件,它们怎么组织,相互之间的交互细节等。它不需要说明组件怎么实现,更确切的说,它可让你先确认和理解组件而无需担心最终怎么去开发它们。
你可将编译器和解释器归为程序语言翻译器。如前面解释的那样,编译器将源程序翻译成机器语言而解释器将之翻译成系列动作(Action)。站在最高角度看翻译器,它包含一个前端(front end)和一个后端(back end)。遵从软件重用法则,你将看到Pascal编译器和Pascal解释器共享前端,但有不同的后端。
翻译器的前端读入源程序然后执行最初的翻译过程。它的主要组件有parser, scanner(更学院派的说法是Lexer即词法分析器),token(最小语言单位,最大词法单元)和source(表示源代码)
paser控制前端的翻译过程。它不断的从scanner读入token,根据token串(就是token模式)判定当前正翻译的高阶语言元素,比如算术表达式,赋值语句,过程申明等。parser检验源程序的语法是否正确。paser干的事情称之为解析(parsing),parser分析源程序然后将之转换。(转换成啥?后面会有,一般为抽象语法树之类的中间层)
scanner一个接一个字符读入源程序的内容,然后构造tokens即源语言的低阶元素。例如Pascal tokens包含关键字如BEGIN、END、IF、THEN和ELSE,标识符即变量、过程、函数名称(identifier,又称ID)以及特殊符号如= := + - *和/ 。scanner干的事情称为扫描(scanning)。scanner扫描源程序,将之分成一个个token。
下图展示了编译器和解释器前端的概念设计:
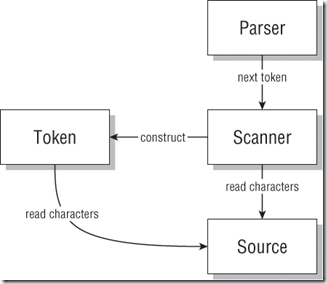
此图中,箭头表示一个组件给另外一个发送命令。parser告诉scanner要下一个token。scanner从source中获取字符然后构造新的token。token 也从source中读入字符。(13章会讲到为何scanner和token组件都需要从source中读取字符)
编译器最终将源程序翻译成机器语言目标代码,所以后端的一个重要组件是代码生成器(目标代码生成器 code generator)。解释器执行程序,所以其后端的首要组件是执行器(executor)。
如果你想让编译器和解释器共享前端,那么它们不同的后端需要有个通用接口用来与前端打交道(也就是只需要将前端传入这个接口即可)。记住前端处理最初的翻译过程。前端生成作为公共接口中间层的中间代码(intermediate code,分析树/语法树,抽象语法树等)和符号表(symbol table)。
中间码(intermediate code)是源程序的预摘要格式(pre-digested,可以理解为在源程序格式和机器语言格式中间的一个摘要格式,一般为分析树parse tree或语法树syntax tree)为方便后端的更有效处理(假设翻译器将塑料翻译成为瓶子,那么源程序为塑料,中间码为瓶盖,瓶身,包装纸,这样后端就能更快的装瓶子)。本书中的中间码是一个驻内存表示源程序语句的树状数据结构(也就是语法树,废话一堆啊)。符号表包含源程序的符号信息(比如标识符)。编译器的后端处理中间码和符号表,生成源程序对应的机器语言。解释器碰到中间码和符号表就直接执行了(通常是树遍历过程)。
为软件重用,你可将中间码和符号表设计成语言无关的结构。换句话说,你可用同样的结构应用于不同的源语言。因此,后端同样可以语言无关,当它处理这些结构(中间码和符号表)是根本不需要知道具体源语言。
下图展示了一个更为复杂的编译器和解释器的概念设计。如果你万事安好,仅需前端知道源语言定义且仅需后端知道区分编译器和解释器。
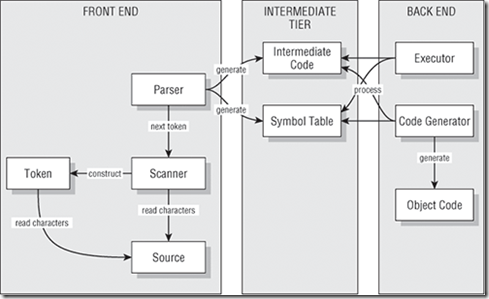
第2章开始通过设计一个编译器解释器框架来充实概念设计。第3章讲的是扫描(scanning)。第4章构建第一个符号表,第五章生成最初的中间码。第6章开始编写执行器(executor)且增量式开发直到14章,其中包含符号调试器和IDE。代码生成直到在15章学了了JVM架构之后的16章才涉及。
语法和语义(syntax and semantics)
编程语言的语法是一系列规则用来断定用此语言写的语句或表达式是否正确。语言的语义传达语句和表达式的具体意思(赋值谁赋给谁,循环终止条件是什么)。举个例子,Pascal的语法告诉我们 i := j+k 是一个有效的赋值语句。它的语义是说将变量j 和k的当前值加起来,然后将和赋给 i。
parser基于源语言的语法和语义执行有关动作。扫描源程序抽取tokens是语法动作。查找赋值语句 := 之后的目标变量是语法动作。将标识符(identifiers) i、j、k当作变量存入符号表或日后在符号表中查找是语义动作,因为parser必须明白当前表达式和赋值的意思才知道得用到符号表。生成代表此赋值语句的中间码属于语义动作。
语法动作尽在前端发生,语义动作在前后端都有。在后端执行程序或者生成目标代码需要知道语句的具体意思,所以是语义动作一部分。中间码和符号表存储语义信息。
词法,语法和语义分析
词法分析是扫描(scanning)的正式说法,所以scanner也称词法分析器(lexical analyzer)。语法分析是parsing(解析,parser的主要任务)的正式称谓,语法分析器就是parser。语义分析主要是检查语义规则是否完整。类型检查(type checking)就是一例,它确保操作符(operator)的操作数(operand)类型保持一致。其它的语义分析操作有构造符号表和生成中间码。